Overview:
Polyglot Probe is a hybrid code search system designed to combine the speed and scalability of Information Retrieval (IR) with the semantic depth of Deep Learning (DL) models. The project aims to address the growing complexity of software development environments, where developers need to quickly find relevant code snippets across vast and heterogeneous codebases. Unlike traditional keyword-based search, which lacks semantic comprehension, Polyglot Probe leverages advanced machine learning models to interpret and match the underlying meaning of code, enabling developers to perform efficient searches across multiple programming languages. This hybrid approach blends the rapid retrieval capabilities of IR with the powerful semantic understanding offered by DL, making it a versatile tool for cross-language code search.
Core Challenges and Approach:
Traditional code search systems primarily rely on keyword-based IR methods, which, while efficient, often produce irrelevant results due to their inability to understand the context or semantics of the query. The integration of DL methods, such as CodeBERT, has improved the relevance of search results by analyzing the deeper semantic structure of code. However, DL models are resource-intensive and often language-specific, making it difficult to scale across large, multilingual codebases.
To overcome these challenges, Polyglot Probe utilizes a dual-module architecture:
Information Retrieval (IR) Module: Focuses on speed and efficiency, using techniques such as inverted indices and fuzzy search to quickly retrieve relevant code snippets based on keyword matches.
Deep Learning (DL) Module: Provides semantic depth by using pretrained code search models that can understand the functional intent of code and match it with user queries.
The hybrid system was designed to answer three key research questions:
RQ1: How does the response time of the hybrid IR-DL approach compare to using IR or DL independently?
RQ2: How does the accuracy and semantic relevance of the hybrid approach compare to DL methods alone?
RQ3: How does the computational resource consumption of the hybrid system compare to standalone IR and DL systems?
Methodologies:
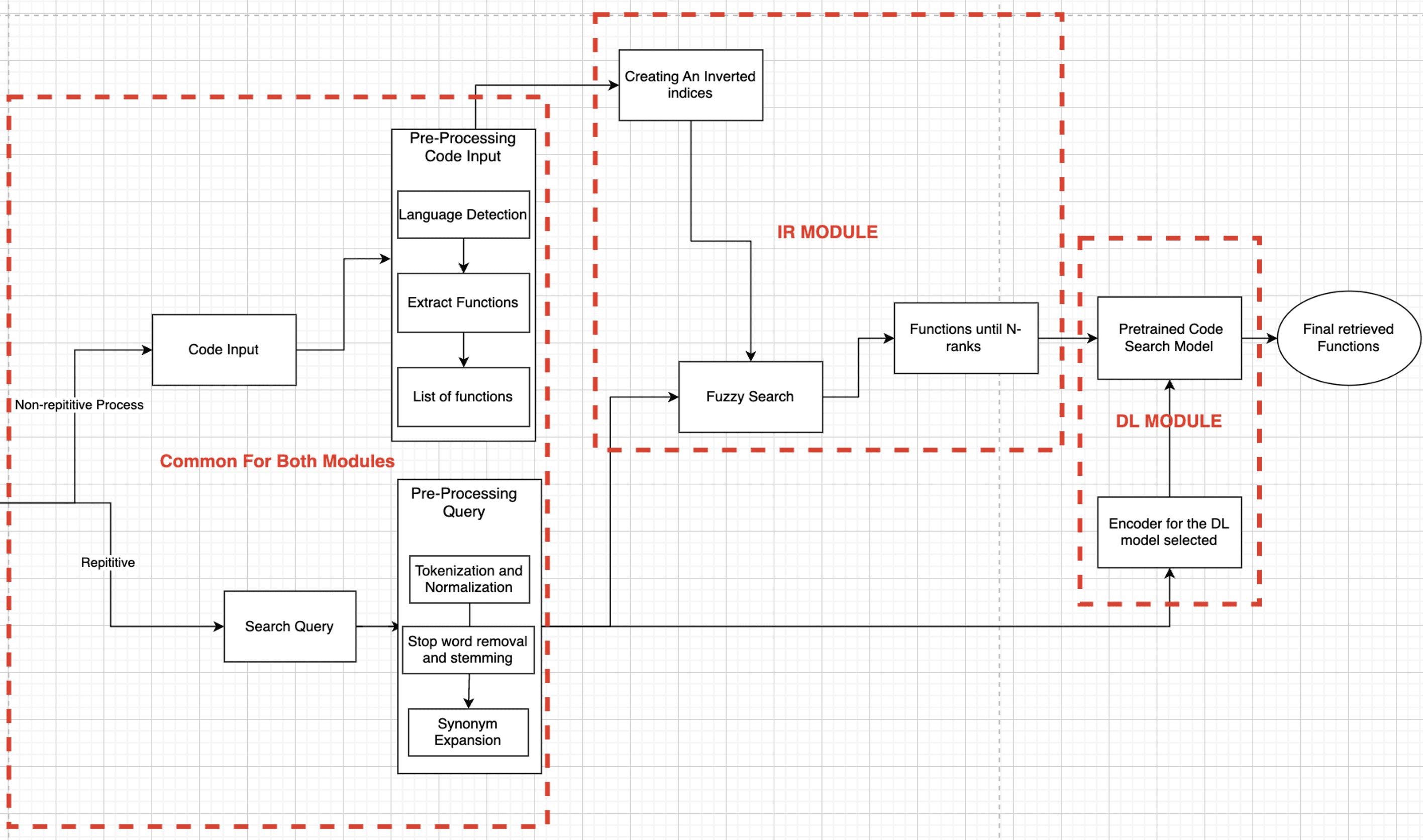
Polyglot Probe’s architecture is divided into non-repetitive (one-time setup tasks) and repetitive processes (dynamic response to user queries). The system integrates both IR and DL models, which share common pre-processing steps to ensure consistency in the handling of both code input and search queries.
Pre-processing:
Code Input Processing: The system first detects the programming language of the input code and extracts individual functions. This ensures that the search is conducted on function-level granularity, facilitating a more meaningful search.
Query Pre-processing: User queries are tokenized, normalized, and expanded using synonym expansion techniques to capture lexical variations in programming terminology. Stop words are removed, and the remaining tokens are stemmed to focus the search on semantically significant elements.
Information Retrieval (IR) Module:
Inverted Indices: A traditional IR mechanism that rapidly retrieves functions based on keyword matches from the indexed codebase.
Fuzzy Search: This allows the system to tolerate minor discrepancies or variations in the search query, improving the robustness of results.
Deep Learning (DL) Module:
Pretrained Code Search Model: The DL module utilizes models such as CodeBERT to provide semantic analysis of the input query. The model’s encoder is selected based on the detected programming language and the query's semantic context.
Semantic Matching: The DL model analyzes the functional intent behind the code and compares it to the user query, ensuring that the search results are contextually relevant and accurate.
Final Retrieval: The outputs from both the IR and DL modules are combined to produce a final ranked list of relevant functions. This merging process ensures that the speed of IR is paired with the depth of DL’s semantic understanding.
Key Features:
Hybrid Architecture: The system combines the best of IR’s efficiency and DL’s semantic analysis to deliver fast and meaningful code search results.
Cross-Language Search Capability: Polyglot Probe is designed to work across multiple programming languages, adapting to the diverse needs of developers working in polyglot environments.
Fuzzy Search Mechanism: The IR module’s fuzzy search accounts for minor errors or variations in user queries, enhancing the system’s tolerance and accuracy.
Iterative Learning: The system learns from each query, refining its model parameters over time to improve search relevance and accuracy.
Results:
The performance of Polyglot Probe was evaluated based on response time, semantic accuracy, and resource utilization:
Response Time Analysis: Polyglot Probe demonstrated a 38.76% improvement in response time compared to standalone DL models like SBert, making it significantly faster for handling large codebases.
Semantic Accuracy and Relevance: While the hybrid system improved speed, occasional semantic mismatches were observed. Despite these outliers, the system’s overall accuracy was competitive with standalone DL models.
Resource Utilization: The hybrid approach consumed fewer computational resources than standalone DL models, indicating that the integration of IR with DL can optimize the trade-off between speed and accuracy without overburdening system resources.
Challenges and Limitations:
Semantic Mismatches: Although the hybrid model improved response times, there were cases where irrelevant items (e.g., incorrect categories in product searches) were returned, revealing the need for further refinement in semantic parsing.
Deep Learning Resource Consumption: Despite improvements, the DL module still requires significant computational power, particularly for large-scale codebases. Future work will focus on optimizing this aspect of the system.
Future Scope
Algorithm Optimization: To improve semantic accuracy, future iterations will explore advanced semantic parsing and context-aware filtering techniques to eliminate mismatches.
Quantitative Human Evaluation: Structured usability studies will provide deeper insights into the user experience and preferences, guiding further refinements.
Broader Dataset Application: Expanding Polyglot Probe’s applicability to larger, more diverse datasets across multiple domains and programming languages will ensure robustness and adaptability.
Real-Time Implementation: Deploying the system in a live code search environment will provide valuable feedback on performance under real-world conditions.
Conclusion
Polyglot Probe demonstrates the potential of a hybrid IR-DL system to bridge the gap between speed and semantic accuracy in code search. By integrating the strengths of both IR and DL, the system offers a powerful solution for developers navigating large, multilingual codebases. Although challenges remain, the promising results pave the way for further optimization and real-time implementation.