Overview
This project focuses on automating the segmentation of 3D medical images for patients suffering from Unilateral Vocal Fold Paralysis (UVFP), a condition that affects the movement of one of the vocal folds due to nerve damage. The project is part of a broader initiative called PhonoSim, which aims to provide a computational tool for surgical planning of Type-1 Thyroplasty, a treatment for UVFP. The goal is to automate the segmentation process, traditionally performed manually, to assist in planning surgeries by generating 3D models of the larynx for Fluid-Structure Interaction (FSI) studies. This system leverages the Insight Segmentation and Registration Toolkit (ITK), ITK-SNAP, and K-means clustering with Otsu filtering to segment the larynx’s anatomical structures from MRI data.
Core Challenges and Approach
The primary challenge of the project was to automate the manual segmentation process for 3D MRI scans of the larynx, particularly for subject-specific computational models that simulate vocal fold function. The segmentation needs to be precise as it informs FSI studies on vocal fold vibrations and phonation characteristics during Type-1 Thyroplasty surgery.
The approach included the following:
Otsu’s Multiple Thresholds Method: Used to automatically determine threshold values for initial segmentation. Otsu's method is applied to separate the image into multiple classes by maximizing the variance between them.
K-means Clustering Refinement: Following the initial segmentation, K-means clustering is used iteratively to refine the boundaries of different tissues by grouping pixels with similar intensities. This step improves the segmentation accuracy, particularly for tissues with overlapping intensities.
ITK-SNAP Snake Tool: An active contour-based segmentation tool that allows precise, interactive refinement of the segmented regions, ensuring the anatomical structures are correctly delineated.
Technical Implementation
ITK Programming Pipeline:
Image Loading and Preprocessing: The MRI images are loaded using ITK’s ImageFileReader, and processed as 3D volumetric data. The segmentation process begins with applying Otsu’s threshold filter, dividing the image into multiple classes based on intensity.
K-means Clustering for Improved Segmentation: K-means clustering is applied after the initial segmentation to iteratively adjust the cluster centers and reassign pixels to the most suitable cluster, refining the segmentation results.
Snake Tool for Post-Segmentation Refinement: The Snake Tool in ITK-SNAP is utilized to fine-tune the segmentation by adjusting the boundaries of structures like the vocal folds, thyroid cartilage, arytenoid cartilage, and cricoid cartilage. This ensures that the 3D models accurately represent the larynx’s anatomy for FSI studies.
Mesh Generation:
After segmentation, the models are smoothed using Meshmixer to remove any irregularities and sharp edges in the segmented components. The smoothed models are then imported into COMSOL Multiphysics to generate tetrahedral meshes, which are used in FSI simulations to analyze vocal fold vibrations and airflow during phonation.
Key Features
Automated 3D Segmentation Pipeline: The system automates the segmentation of key laryngeal structures (vocal folds, thyroid cartilage, arytenoid cartilage, cricoid cartilage) from 3D MRI images using Otsu’s method and K-means clustering, drastically reducing the time required compared to manual segmentation.
High-Resolution 3D Models for FSI Studies: The segmented models are used in computational FSI simulations, enabling surgeons to predict the effects of Type-1 Thyroplasty on vocal fold function. The high-resolution 3D models provide critical insights into the airflow and vibration patterns during phonation.
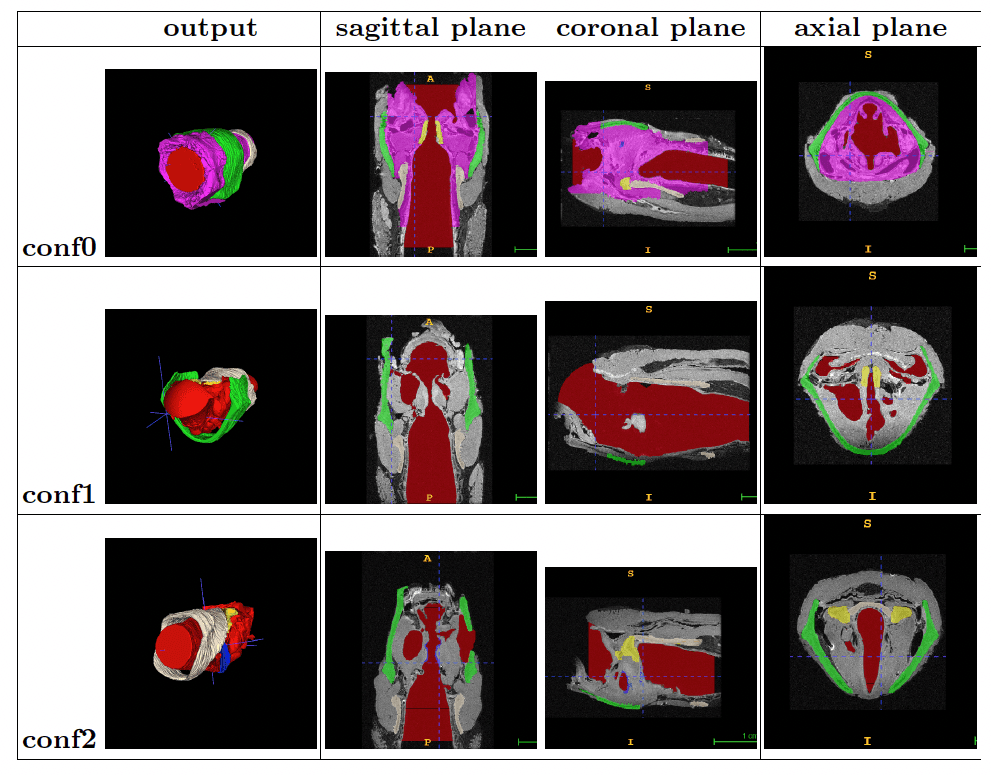
Customizable Parameters for Segmentation: The number of clusters for K-means can be adjusted to achieve the desired granularity for different anatomical structures, making the segmentation process adaptable to various datasets.
Results
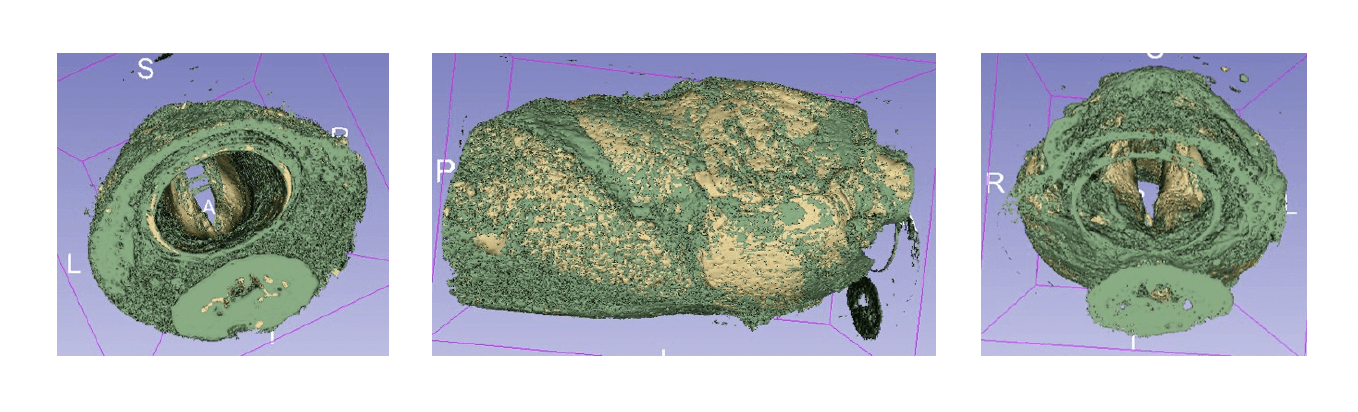
The automated segmentation pipeline was successfully applied to a dataset of rabbit larynx models, with the segmented models used for subsequent FSI simulations. The results demonstrated that the automated process could generate accurate 3D models of the larynx with minimal manual intervention, reducing the time required for segmentation from 2 days to a few hours. This significantly accelerates the surgical planning process for UVFP patients undergoing Type-1 Thyroplasty.
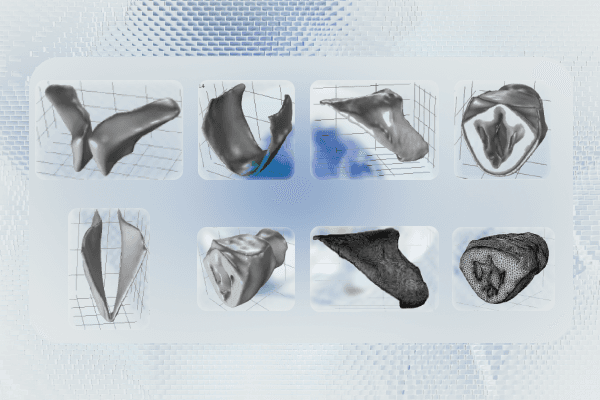
Manual Segmentation: Identified five components of the larynx for segmentation: vocal fold cover, thyroid cartilage, arytenoid cartilage, cricoid cartilage, and lumen surface. These structures are critical for simulating airflow and vocal fold vibration.
K-means Clustering: Achieved accurate segmentation of the laryngeal anatomy with K-values ranging from 2 to 5. The models produced distinct clusters for each anatomical structure, facilitating precise FSI simulations.
Mesh Generation: High-quality meshes were generated for FSI simulations, allowing the analysis of implant positioning and its effects on vocal fold function.
Challenges and Limitations
While the automated segmentation process significantly reduced the time required for manual segmentation, several challenges were encountered:
Otsu’s Limitations: Otsu’s method struggles with images where intensity separations are not clear, leading to suboptimal segmentation in regions with overlapping tissue intensities.
K-means Sensitivity: The K-means algorithm is sensitive to initial cluster centers and lacks spatial awareness, which can limit its effectiveness in some complex medical images.
Data Limitations for Deep Learning Approaches: The project considered using deep learning-based segmentation methods (e.g., CNNs, U-Nets), but the lack of sufficient labeled data for training posed a significant challenge.
Future Scope
The next phase of the project aims to integrate neural networks for further improving the segmentation process, leveraging techniques such as transfer learning and semi-supervised learning to address the data limitations. Additionally, the PhonoSim system, which this project supports, seeks to reduce the surgical relapse rate of Type-1 Thyroplasty by providing surgeons with more accurate simulations of implant positioning. As this project progresses, automating the segmentation process will be critical for transitioning PhonoSim to human trials and achieving faster, more effective surgical planning.
Conclusion
This project marks a significant step toward automating the medical image segmentation process for UVFP treatment. By combining traditional segmentation methods with modern computational techniques, the system offers a practical solution for generating high-resolution 3D models of the larynx. These models play a crucial role in improving surgical outcomes for patients undergoing Type-1 Thyroplasty, potentially reducing the surgical relapse rate and enhancing patient quality of life.